

About Simudyne
Last updated on 16th July 2024
Simudyne is a Software Development Kit (SDK) that allows users to build models. These models empower users to reflect the complexity of the real world. The SDK can build tiny details and general concepts into its models, unifying macro and micro modelling.
The Simudyne SDK can model a wide variety of situations and concepts, including the increase of complexity over time, the emergence of new entities, the way a system responds to feedback, and the process of contagion.
The Hierarchy of Modules is as below:
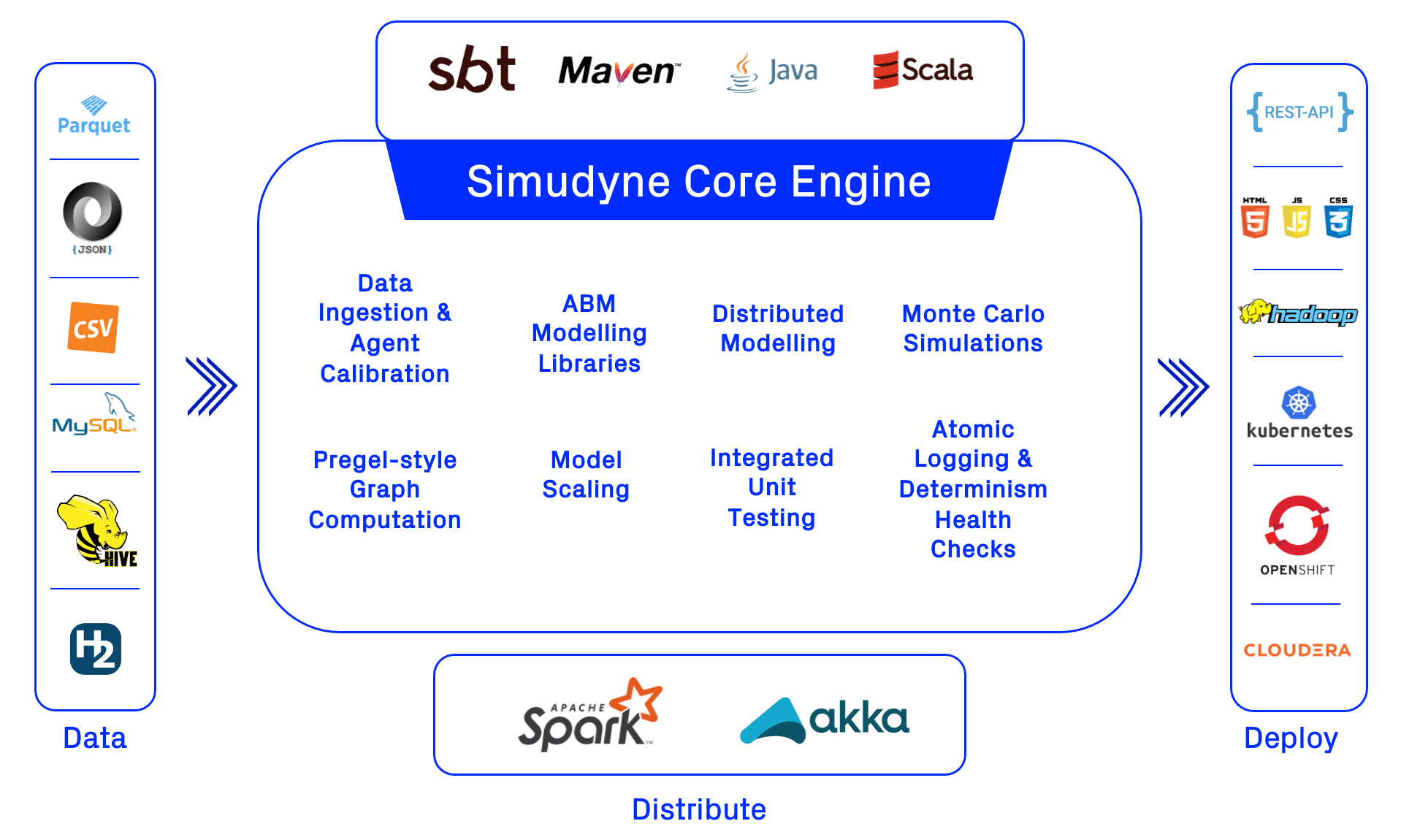
Overview of the tech stack and capabilities of the SDK:
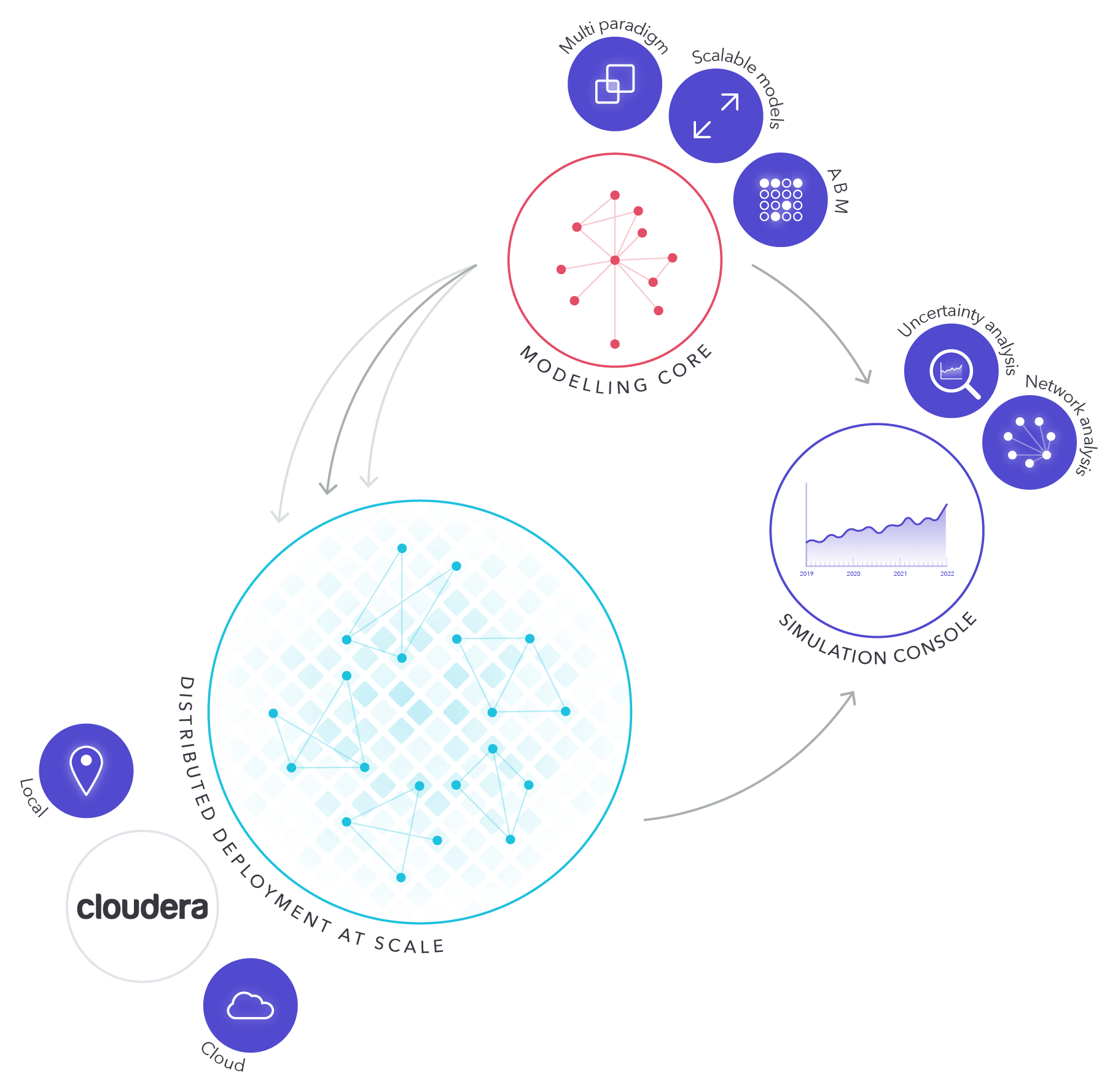
Modelling Core
The modelling core is the backbone of the Simudyne SDK. It is a collection of libraries which emphasizes speed and processing power in building highly flexible models. Models built with the core are also engineered to be easily maintainable.
Agent-Based Modelling (ABM)
The modelling core uses objects called agents to mirror the real world at every level of detail. These agents communicate with each other by sending messages. The agents and messages mimic real world interactions, as well as the effects of those interactions over time. Agents are defined by the data they hold and the actions they take, either internally or when interacting with other agents. More on agents, networks and interactions can be found in Agents & Network/Graph.
Distributed Deployment
Models built with the Simudyne SDK are optimized to run quickly on either single machines or distributed systems. They can be distributed over any number of nodes in larger systems. These nodes can be local hardware or on a cloud, as necessary. When many copies of the same model are running on nodes, the SDK returns a distribution of outcomes combining all successful runs. Modellers can use this distribution to predict the chances of desirable and undesirable future scenarios.
Simudyne SDK supports deployment on Cloudera, Red Hat OpenShift, or a custom Hadoop cluster. More information can be found in Distribution.
Simulation Console
Simudyne provides a simulation console so modellers can monitor their models. The console allows modellers to inspect their results during a model's runtime and after it is finished. Data reporting allows modellers to inspect results through agents or through larger modelled pieces. Modellers can also debug and share their results from the console after their models have finished running.
The console is an optional feature that can be bypassed for larger batch runs or replaced by a bespoke console or dashboard using the Rest API. More information can be found in Console.
Simulation Control
Modellers can choose models and run them over time for specific sets of input. Rerunning models multiple times with different inputs is a reliable way to determine which factors drive the model's progress. Identifying these drivers can sometimes be as important as the model results.
Uncertainty Analysis
The simulation console can display the distribution of outcomes from models running on distributed systems. This visual representation illustrates the uncertainty present in the models. Since models run with calibrated parameters, it is important to know how well those parameters reflect the real world. If they don't echo the real world well enough, the model won't allow relevant predictions.
Uncertainty is especially important if a black swan occurs while a model runs. A black swan is an unexpected event that has a major effect on the results of a model. It is important to analyze these events in relation to inputs, rather than to rationalize them after the fact, because basing further models on a black swan can drastically change results and predictions.
Extensive analysis of results requires setting up output methods to examine agents and interactions in further detail. More on data outputting methods can be found in Input & Output.
Network Analysis
The simulation console allows modellers to study the structure of their model while the model is running. Analyzing the agent network in this way provides insight into the ways agents can affect each other when they're not connected directly. Indirect effects on agents can sometimes have large effects in seemingly simple models.